
Survival guide: how to migrate from the Firebase Realtime Database to Cloud Firestore
Published Dec 12, 2017 • Last updated Nov 02, 2022 • 35 min read

The long-awaited database revamp is here!
Ever since Google’s new mobile SDKs were announced two years ago at I/O, the Firebase empire has been ever-expanding. It now supports more and more features, such as Cloud Functions, phone authentication, and performance monitoring. However, one SDK that hasn’t changed much is the Firebase Realtime Database (RTDB).
The RTDB hasn’t received any major updates — and not because it was a perfect API. Far from it. If you’ve read about Pier Bover’s experience, or have used the Firebase RTDB yourself, these problems might sound familiar:
No way to query your data properly […] and dumb data modelling.
So what’s next? How is Google going to solve these limitations? Instead of releasing a version 4.0 of the RTDB, which would be messy and painful for everyone, Google is using what it learned from the Firebase Realtime Database’s faults. And they’re completely redesigning and rewriting it from scratch into a new database: Cloud Firestore.
The RTDB isn’t going away — that would cause a huge crisis. But going forward, Cloud Firestore will receive most of the attention and love.
This article is going to delve deep into Google’s long-awaited database revamp, mostly from an Android RTDB developer’s point of view. In addition, the article is intended as a replacement for hours of pouring over documentation to build a mental model of the new SDK.
Background #
Unless you’ve just recently joined the Firebase party, you’ve probably heard of the Google Cloud Platform (GCP). Except for the RTDB, all other Firebase server products, like Cloud Functions and Firebase Storage, are usually rebrands of existing GCP solutions with extra bells and whistles — plus Firebase integration and branding.
However, the RTDB was ported over from the pre-Google Firebase. It turns out that the database actually used to be a chat service. They only decided to strip out the UI and turn it into an SDK after the company shifted its focus. With the never-ending swarm of chat app samples, you’d think they’re still a little bit nostalgic.
On the other hand, Cloud Firestore is built off GCP’s Google Cloud Datastore, a NoSQL database with near-infinite scalability and powerful querying abilities. The Firebase-branded Cloud Datastore adds the expected realtime capabilities and, of course, integration with other Firebase services such as Authentication and Cloud Functions.
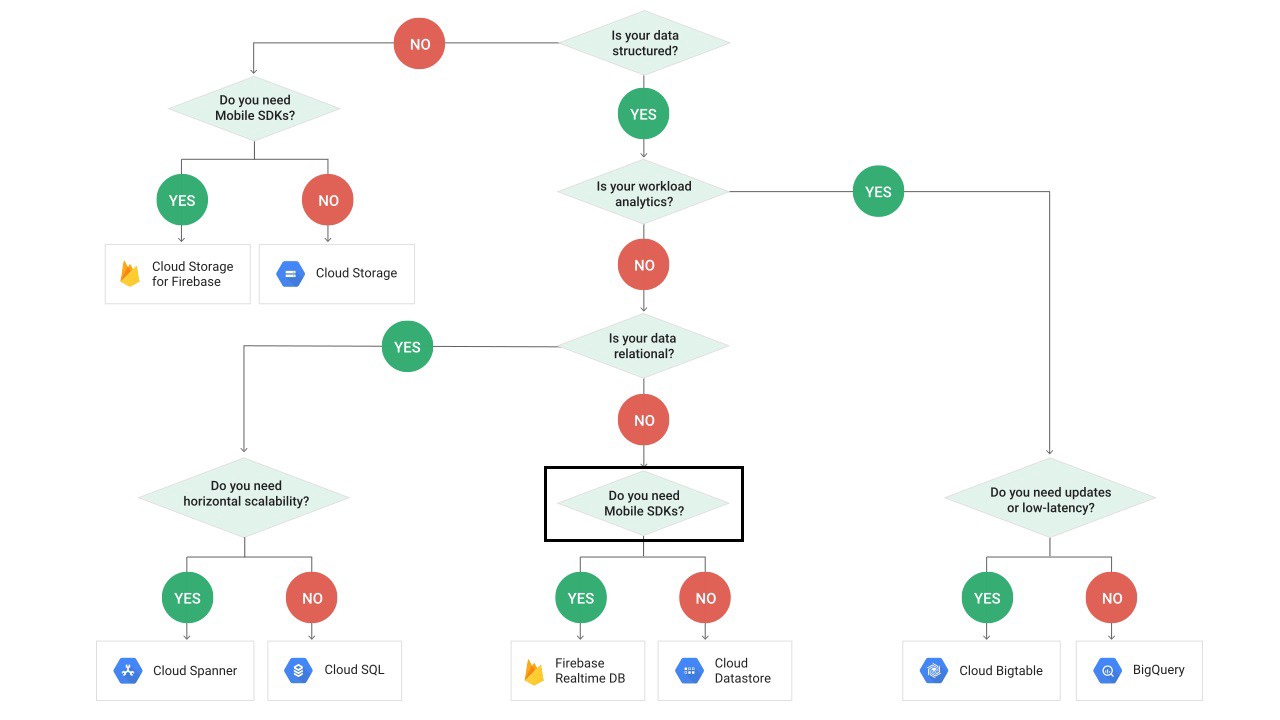
Pre-Firestore flow chart. You now get the best of both Firebase and Datastore!
For database fans, Cloud Datastore is a multi-region, synchronously-replicated database that uses ACID transactions. This means that once Google says your write is committed, a dinosaur-age meteor could take out a region and your data would still be safe and sound, ready to be queried.
Now I’m not saying we humans would fare so well… but at least your data would still be rock solid! Oh, and it uses atomic clocks — now if that isn’t cool, I don’t know what is!
Now that you have a basic understanding of why Google decided to create a completely new Firebase branded database and where it came from, let’s get started!
For the rest of this article, I’ll be using examples from apps I’ve built (so no chat app samples! 😁). Specifically, I’ll be using examples from Robot Scouter, an app to help FIRST Robotics Competition teams make data-driven decisions during competitions.
The app’s basic purpose is to allow users to collect data about other teams in units called scouts. These scouts can be based off customizable templates. Scouts and templates are composed of metrics, which are different types of data a user can collect. Templates are standalone objects, but scouts are implicitly owned by a team.
Individual teams and templates can be shared with other users, but the scouts will follow a team around wherever it goes since the team owns them.
Data structures #
Let’s start by looking at what the Robot Scouter data structure looked like with the RTDB. Take a deep breath, there’s a lot to scroll through:
Well that's a hot mess!
All we really wanted was a teams, templates, and users collection. Instead, we had to denormalize our data to accommodate for the RTDB’s deep-by-default queries. Remember, if we query a node with the RTDB, we also get all child nodes.
Now let’s take a look at the equivalent Cloud Firestore data structure:
There we go, that's much better!
The Cloud Firestore data structure is easier to understand and much shorter than the RTDB structure. This is thanks to nested refs versus being forced to denormalize everything in the RTDB.
Data structure differences #
The first major difference you’ll notice is the lack of denormalization. In the Cloud Firestore data structure, we declare our teams ref and put each team directly inside that ref instead of flattening it out. Similarly, we’ve merged the template-indices directly into the templates ref.
You might have also noticed that our scouts are now directly placed inside a team instead of being in a separate indices ref. Your first reaction might have been “Wait, you’re going to waste all the user’s data! Don’t do that!” This is the beauty of Cloud Firestore: queries are “shallow” by default.
I put the word shallow in quotes because technically, you could nest a huge amount of data in your documents. But we’ll talk about why you shouldn’t do that later. Wait a sec, what’s a document? Cloud Firestore has two basic building blocks: collections and documents.

Cloud Firestore's fundamental building blocks
Collections in Firestore are the equivalent of a ref in the RTDB with a huge list of child nodes that each contain objects. If you scroll back up to the Firestore data structure, you’ll notice that teams, templates, and users are all collections. They each contain a whole bunch of objects — and in Firestore, these objects are called documents.
Documents would be your conventional object node in the RTDB. However, in Firestore they’re a little special: documents are explicitly owned by a collection. In the RTDB, you could put pretty much anything anywhere. Cloud Firestore brings in a little sanity and uses an alternating pattern of collections and documents which looks a little like this: collection1/document1/collection2/document2/....
While this pattern could feel constraining at first, I’ve found it helpful in forcing me to design a neatly organized data structure. You’ll notice that my scouts collection now properly resides within a team document. I only had to split it out in the RTDB so that my users wouldn’t have to download all their scouts when looking at a team. In Cloud Firestore, teams have explicit ownership of a set of scouts without having to download them when loading the team.
A little more on documents #
In the RTDB, you had a free-flowing model with 3 core data types: booleans, strings, and numbers. Things like lists and maps were either an afterthought or just part of how you queried for data in the RTDB.
On the other hand, with Firestore, you have a very clear cut structure: collections contain documents, and documents contain fields and links to one or more subcollections.
Subcollection is just a fancy term for another list of objects owned by a document — except you won’t get that list when querying the document. This is because documents don’t technically contain subcollections. They just link to them. Hence why we can put our scouts collection inside the team document — or link to it, if you will.
On top of containing subcollections, documents in Firestore support a vast array of data types with more on the horizon. For now, here are the supported types:
- Boolean
- String
- Number
- Raw bytes (if that’s your style 😁)
- Dates and time
- Geo points
- Refs
- Arrays and maps
- Null!
Yes, null is now an explicitly defined data type in Cloud Firestore. If you set a document equal to a Java object whose getter returns null, the field will still show up in the Firebase Console with the null data type.
Well ok, so what? Adding the null data type makes field deletion explicit. In the RTDB, setting something to null is the same as deleting it. But in Firestore, to delete a field you must set its value to FieldValue.delete(). On a similar note, ServerValue.TIMESTAMP has become FieldValue.serverTimestamp().
In addition, the null data type sort of enables migrations. Using the DocumentSnapshot#contains(…) method, you could check to see if a field exists and do something if it doesn’t. A better strategy would be to use a Cloud Function, but that’s beyond the scope of this article.
You’ll notice documents still support arrays and maps, but how does that work if documents can only contain fields? Remember how I said you could technically nest your data? Here’s that special case: Firestore lets you store explicitly defined arrays and maps within documents, as opposed to creating a subcollection.
Note: there are several limits to documents in Firestore. Specifically, there is a 1MB size limit, a maximum of 20,000 properties per document, and a 500 level deep object nesting limit.
Properties are different from fields in that they account for all nested fields, not just the conventional root level field. In addition, as of this writing, updating a large array or map rewrites the entire array/map and will have abysmal performance on large data structures. Please use subcollections instead!
Because Google loves to rename things, document “keys” from the RTDB are now called ids. The last path segment of a collection or document is called an id, meaning teams/teamId1 is a document with id teamId1 under a collection with id teams. Nothing too groundbreaking, but it’s always nice to be on the same page when it comes to terminology.
Finally, since documents are one of the fundamental building blocks of Firestore, you can only get a full document. This is unlike the RTDB where you could query for as specific a field as you liked.
Storing and retrieving data #
Now that you have a basic understanding of Firestore’s two fundamental building blocks — collections and documents — it’s time to look at how we can store and then get our data.
The Cloud Firestore API surface is a massive improvement over the RTDB’s. So you’re unlikely to find any methods that were simply ported over (though some will look familiar).
Storing data #
The first distinction you’ll notice from the RTDB is the slightly messy and spread out way of creating and updating data. Not to worry, it’ll all make sense in just a bit.
Unlike our pets, there are no stray documents — they must all live under a collection. This means we have two places from where we can add data: a collection to add documents, and a document to add, update, or remove fields.
Let’s start by looking at the simplest way to add data, though collections:
Well that wasn't hard!
We’re saying that within the teams collection, we want to add a document with all the fields from the Team POJO.
Now let’s look at the more interesting case where we change document data:
Ouch, there's a lot more to cover!
The first thing to note is our scoutRef: it creates a scout inside our scouts collection, which in turn exists under a team document. As a URL, it would look something like this: teams/teamId/scouts/newScoutId.
The document() method returns a new DocumentReference with a random id. It’s a truly random id in the sense that it’s no longer based off of a timestamp.
Those familiar with the RTDB will know that the push() method creates a pseudo-random key using a timestamp for native temporal sorting. Since Cloud Firestore aims to move away from being a chat-oriented database, it doesn’t make sense for them to use temporal sorting as the default mechanism.
As such, this means you’ll have to manually add a timestamp field when relevant. In theory, you could use the timestamp as a document id for sorting, but that reduces flexibility.
The DocumentReference contains a plethora of different ways to set and update data, from using maps and POJOs to supplying varargs. There’s a slice of pie for everyone! I’m going to focus on the POJO and specific field update methods, since those are the ones I’ve found to be most useful.
The first method you’ll notice and probably use most often is set(Object). This one is fairly simple: it behaves exactly like the Java’s Map#set(key, value) method. If no document exists, it will create a new one. Otherwise, if a document exists, it will be overwritten.
However, Google also provides SetOptions with various merge combinations to only overwrite some fields. I’ve found this to be useful when updating a user’s profile, for example. I’ll set/update their name, email, and photoUrl, but not the lastLogin field, since it isn’t part of my User POJO.
If you want to ensure a document exists before performing an update, the update(String, Object, Object…) method will be the right tool for the job. In this case, we are updating a specific field with a new value. If the document doesn’t exist prior to calling the update method, the update will fail. If you’d like, you can also update multiple fields at once by alternating key/value pairs in the varargs. (I personally prefer using multiple updates in a WriteBatch, which I’ll discuss later.)
What if you wanted to update a nested field inside an object? For this use case, Google provides the FieldPath#of(String…) method. Each item inside the varargs array brings you deeper inside a nested field’s path — technically an object. For example, FieldPath.of("rootField", "child") updates the following field: myDocument/rootField/child.
Similarly, Firestore also supports the dot notation syntax which lets you reference that same field like so: rootField.child.
Cloud Firestore also includes an awesome new way to batch writes with the WriteBatch class. It’s very similar to the SharedPreferences.Editor you’ll find on Android. You can add or update documents in the WriteBatch instance, but they won’t be visible to your app until you call WriteBatch#commit(). I’ve created the standard Kotlin improvement where the batch lifecycle is managed for you — feel free to copypasta.
The last important API change to note when managing data is how to delete it. Cloud Firestore has a method to delete a document — DocumentReference#delete() — but no easy way to delete an entire collection. Google provides a code sample with documentation on how to delete all documents in a collection, but they haven’t baked it into the SDK yet. This is because this method could easily fail under extreme conditions when attempting to delete thousands or even millions of documents buried in various subcollections. But Google does say they’re working on it.
In addition, their sample doesn’t delete subcollections either — only documents under the collection. Google doesn’t yet have a clear solution to that problem on Android either. Still, they’re providing a CLI/NodeJS API as part of firebase-tools that you can use to delete all subcollections manually or from a Cloud Function.
In my case, I don’t let users create random collection names so I can delete all my subcollections by getting their parent document ids.
I’ve rewritten their sample with more functionality and a cleaner API in Kotlin:
Deleting all scouts and their associated metrics under a team
Whew, we’ve covered most everything you’ll need to know about storing data!
Retrieving data #
The first thing to note is that I’m using the word retrieving instead of reading. This is because Firestore provides two very clear-cut ways of retrieving data: either through a single read (aka a get), or through a series of reads (aka a snapshot listener).
Getting data #
Let’s start by exploring ways to read data once. In the RTDB, you had the addListenerForSingleValueEvent() method, but it was full of bugs and edge cases. I think Frank van Puffelen — a Googler — summed it up best:
The best way to solve this is to not use a single-value listener. #
Yeah. There’s definitely a problem when you tell your own users not to use a product you’re selling.
Cloud Firestore completely revamps the entire data retrieval experience with better and more intuitive APIs.
First, a note on offline capabilities. The RTDB wasn’t designed as an offline first database — offline capabilities were more of an afterthought since the db was ported over from pre-Google Firebase. On the other hand, Cloud Firestore isn’t exactly an offline first database since it’s also designed to be realtime. But I would consider its offline capabilities to be first class citizens along with the realtime stuff.
Given those improvements, offline support is enabled by default (except for web), and data is stored in a SQLite database using Android’s native APIs. I don’t know about you, but I find it more than a little ironic that a NoSQL database needs a SQL database to work.
For the curious, Firestore’s SQL database is named firestore.$firebaseAppName.$projectId.(default). In addition, they lock it using PRAGMA locking_mode = EXCLUSIVE to improve performance and prevent multi-process access. If you’re really curious, here are the tables and queries I’ve found so far:
The SQL behind the NoSQL
I did some more digging and found a few other things. For example, GRCP devs really like enums. You know what they say, “If something is bad for you, do more of it!”
There are 95 enums in here — that must be some kind of record!
With that aside, let’s explore our first method: DocumentReference#get(). This is the simplest and most basic way to retrieve data: it replaces the RTBD’s addListenerForSingleValueEvent() method with several notable improvements.
First, it returns a Task<DocumentSnapshot>. This makes far more sense than using the same event model API as you would for snapshot listeners from the RTDB. Now, you can use all of Play Services’s lovely Task APIs to add your success and failure listeners. You can even attach them to an activity lifecycle if needed.
Second, offline support actually makes sense when using get(). If the device is online, you’ll get the most up-to-date copy of your data directly from the server. If the device is offline and has cached data, you’ll immediately get that cache. And finally, if there’s no cached data, you’ll immediately get a failure event with error code FirebaseFirestoreException.Code#UNAVAILABLE. TLDR: you’ll get the most up-to-date data that can be retrieved in the device’s current network state.
I’ll dive into queries in just a bit, but for now, I’ll just mention that the Query#get() method returning a Task<QuerySnapshot> is also available with the same behavior as described above.
In other notable news, the Query#getRef() method was removed to support a possible future where a query doesn’t depend on a CollectionReference. Just like in the RTDB, CollectionReference extends Query to support easily starting a query. But in the RTDB, you used to be able to jump back and forth between queries and refs. This is no longer the case in Firestore. I’ve found this to be a mild inconvenience, but nothing too major.
Listening for data #
Of course, this is Firebase — so we also want our sweet, sweet realtime capabilities. The API surface for queries was also completely revamped to be cleaner and clearer.
Let’s start by looking at how you would get all the documents in a collection.
Do you remember the difference between addValueEventListener() and addChildEventListener() from the RTDB? And have you ever wished you could get a bit of both worlds? Me too. Thankfully, this is exactly what Google has done with Cloud Firestore: you’ll get the entire list of documents and a list of changes and possible exceptions all in one monolithic callback.
I’m not sure I like the combined data/exception model, but it makes sense in a Java 8 world with functional interfaces. For example, here’s a nice lambdazed callback:
Not bad, right? This is much cleaner than the RTDB callback(s).
Let’s start with the error case, since that’s what all good developers should think about first, right? 😁
FirebaseFirestoreException is relatively simple compared to the RTDB. First, it’s actually an exception! Whaaat? An error that actually extends Exception — who would have thought!? This makes crash reporting dead simple: just report the exception which includes error codes and everything. It’ll look nice and pretty like this:
Exception com.google.firebase.firestore.FirebaseFirestoreException: PERMISSION_DENIED: Missing or insufficient permissions.
With that aside, let’s move on to the exciting stuff: QuerySnapshot. It contains document changes, the full list of documents, and some other data I’ll explore in just a bit.
I’ve provided links to all the relevant classes, because I’m going to skip over those in favor of using FirebaseUI. I’ll explore this in depth later when we’re putting everything together.
As a quick summary, you can differentiate between different update types, iterate over the QuerySnapshot to get each DocumentSnapshot in pretty Java 5 for loops, convert the entire list to a bunch of POJOs (not recommended for performance reasons, will discuss later), and convert individual documents to a POJO or access specific field information. So basically everything you’d expect from a nice API.
However, I do want to explore listener registration and QueryListenOptions — a new way get information about your offline status.
Those two concepts will be easier to understand with a code sample, so here goes nothing:
Not too pretty. 😕
The basic idea of this method is to wait until data is received directly from the server.
The first thing to note is listener registration — it’s kinda painful. I’ve spent some time thinking about it, and I’ve come to the conclusion that Google made the right choice. It should be painful to nudge you in the right direction.
Ok, let’s back up a bit. In the RTDB, you’re used to removing the listener callback instance directly from the Query class. This was a nice API, but it let you do terrible things like accidentally leak your Contexts. The new API returns a ListenerRegistration whose only method is remove() — pretty self-explanatory.
This new listener registration method forces you to rethink your approach to retrieving data. Here’s a simple guide to choosing which API to use:
- If your data isn’t being displayed to the user, you should probably be using one of the
get()methods that use the same listener registration mechanism internally as shown above. (Google’s suffering for you 😁) - If your data is tied to UI, you should use the
addSnapshotListener(Activity, ...)variant which automatically manages lifecycle for you by unregistering inActivity#onStop(). - If your data is tied to a list like a
RecyclerView, hold your horses — I’m going to detail the much-improved FirebaseUI library later on, which will automatically handle nearly everything for you. - If you don’t fall into the above categories, then you should consider using FirebaseUI (again!) which I’ll detail later (again!). Otherwise, just avert your eyes. 😜
Ok, so the listener registration API is painful, but intentionally so to nudge you into picking the right tool for the job.
Now let’s take a look at the QueryListenOptions. Remember how I said Cloud Firestore considers offline support a first class citizen? Here’s where they address the final pain points devs experienced with the RTDB. They still don’t offer a way to customize how your data is cached, but personally, I don’t see any value in that kind of customization: the API should be smart enough to manage that stuff for me — and it is with Firestore.
The first method you’ll find in your listen options is called includeQueryMetadataChanges() and the second is called includeDocumentMetadataChanges(). Both of these are tied to SnapshotMetadata’s isFromCache() and hasPendingWrites() respectively.
For a given QuerySnapshot, isFromCache() will have the same value for each DocumentSnapshot’s metadata and for query’s metadata itself. This means you can find out if your data is up-to-date with the server either from a QuerySnapshot or from a DocumentSnapshot — it doesn’t matter. Either the entire query is considered to be up-to-date, or not — there’s no in-between state like the API would have you believe. In theory, one of your documents could actually be up-to-date if another active listener includes that document in its results, but Google has opted for simplicity and doesn’t surface this information in the API.
On the other hand, hasPendingWrites() can have a different value for each DocumentSnapshot. This is what you’d expect, and there aren’t any special edge cases or tricks.
To summarize:
- Use
includeQueryMetadataChanges()if you’d like know whether a query and all its documents are up-to-date with the server. - Use
includeDocumentMetadataChanges()if you’d like to know about per-document changes in pending write status.
One last tidbit before I move on: all the addSnapshotListener methods are also duplicated in DocumentReference so you can get updates about just a single document if needed.
Querying data #
Ahhh… More than 3,000 words later, we finally get into the meat of Cloud Firestore.
I don’t have any statistics to back this statement, but I think that by far the biggest complaint about the RTDB is the lack of proper querying abilities. Here’s another quote from Pier Bover’s article:
Really? Google is providing a data service with no searching or filtering capabilities? Yeah. Really. #
Since Cloud Firestore is backed by GCP’s Cloud Datastore, queries are first class citizens.
Let’s go back to our new and improved data structure. But to save you from aggressively scrolling up for a minute, here it is reposted:
Since we have an infinite list of teams, how do we get a specific user’s teams? In the RTDB, we would have stored the data following a pattern akin to this: teams/uid1/teamKey1. With Cloud Firestore, we flipflop the user’s id and the team id so that the pattern looks more like this: teams/teamKey1/owners/uid1.
Now we can query for the user’s teams like so:
Pretty simple, right?
We’re telling Firestore to look at the owners field in all documents under the teams collection for a document with id uid equal to true.
Unfortunately, this method doesn’t support ordering. So instead, we’ll write the following query:
A little hacky, but it works.
This query has the advantage of supporting ordering, but it comes with similar issues to the RTDB: updating those sorting values is going to be a pain.
In my case, the sorting values are always static: they’re either the team number or the document creation timestamp. Because I’m never going to update those sorting values, this query works perfectly for me.
On the other hand, you might have different constraints — remember, I need my data to be structured in a way that supports easily sharing teams and templates across users. If this isn’t your case, you should take a look at Google’s suggested structures and their solutions to common problems.
Since the queries you write will depend on your app’s specific constraints, I’m not going to delve into them too much. But I will point out that Cloud Firestore supports compound queries.
One last notable change from the RTDB before I move on: priorities aren’t a thing anymore. Since Firestore properly supports ordering and querying, they opted to remove the .priority field you could find in the RTDB from Firestore documents.
However, if you still want to order your documents by id for some reason, Firestore provides the FieldPath#documentId() method for exactly that purpose.
Security rules #
Security rules in Firestore have gotten a bit worse for wear, in my opinion. However, for those familiar with Firebase Storage, you’ll feel right at home. Google has merged its database rules technology with the rest of GCP.
On the other hand, for those coming from a JSON world with the RTDB, Firestore’s new rules syntax is a bit convoluted. If you deploy rules in your CI build, you’ll have to either edit them in the Firebase Console and then copy the rules to your local editor, or edit them in a txt file. Gross.
Here’s what the simplest possible set of rules looks like:
Hmmm, boilerplate anyone?
Google actually has surprisingly good documentation on security rules — I’ve personally been able to solve nearly all of my problems just by reading the docs. I will still go over a few gotchas from the RTDB developer’s point of view (assuming you’ve at least skimmed the docs).
First, the read keyword is an array of get and list, and the write keyword is an array of create, update, and delete . Each keyword is self-explanatory except for list — it applies to queries, meaning not a single “get.” Each of these keywords can be used individually, but the read and write ones were provided for convenience.
On a related note, you’ll usually end up splitting up your write keywords to allow deletion. For example, using the request object to check write validity fails if a user is trying to delete the data in question. In addition, if you’re checking to see if someone is an owner, you’ve introduced a security flaw. Anyone can add themselves, since the new data is being checked instead of the old.
Here’s some sample rules to put those words into code:
Standard write configuration
There’s another major difference from the RTDB developer’s perspective: rule evaluation is shallow by default. This goes along nicely with the (sub)collection model, but requires a small shift in mindset.
For example, the request variable does not contain information about its parent document. At first, I wanted to check from a document inside a subcollection if a parent document had some field. But of course this doesn’t work, because the subcollection is just a link inside of the parent document.
Because rules are shallow, you have to be careful when using the double star operator (variable=**) since its resources won’t contain parent document information. In addition, there’s some funkiness with the variable:
A little tricky at first, but easy to get used to
FirebaseUI #
Now that you have a complete understanding of Cloud Firestore’s capabilities along with its differences and improvements from the RTDB, let’s take a look at how we can put all of this together to build some UI.
FirebaseUI consists of several components including auth and storage, but we’ll focus on the firestore module.
In the querying section, I mentioned several times that FirebaseUI could help us. We’ll start by looking at how we can improve upon QuerySnapshot’s toObjects() method.
There are two main problems with using the toObjects() method:
- Performance is going to suck, especially with large lists. On every update your
EventListenerreceives, Firestore will recreate every object — changed or not — all at once using reflection. Ouch. - There’s no customization available. For example, I like my model objects to have a
reffield so that I can easily update them later. However, I don’t want to actually store the ref in the database because that would just be pointless duplication.
While you might be thinking, “well, I’ll just create a list and update it whenever new objects come in,” FirebaseUI does exactly that for you so you don’t have to write boilerplate code.
FirestoreArray — as it’s aptly named — is an array of snapshots from Firestore converted to your POJO model objects. Its constructor takes in a Firestore Query, a SnapshotParser<T>, and optionally, query options. It starts listening for data whenever you add one or more ChangeEventListeners and will automatically stop listening when the last listener is removed.
The ChangeEventListener will notify you when each object changes, when an entire update has been processed, and when any errors occur. The SnapshotParser<T> has a single method — parseSnapshot — which is responsible for converting each DocumentSnapshot into your model POJO of type T.
Since FirestoreArray implements List<T>, this setup lets you easily listen for updates to your model objects with minimal hassle.
In terms of performance, FirestoreArray uses Android’s native LruCache to lazily parse objects as needed. For now, we’ve set the max cache size to 100, but if you feel you’ll need a bigger (or smaller) cache size, we’d love to know your use cases in a GitHub issue.
Since this is FirebaseUI, we let you easily map your FirestoreArray to a RecyclerView with the FirestoreRecyclerAdapter and its FirestoreRecyclerOptions.
There are a few interesting recycler options, notably the ability to pass in an Android Architecture Components LifecycleOwner with which we’ll automatically manage the FirestoreArray’s lifecycle for you.
Ok, that was a lot of words. Here’s what it would look like all put together with Architecture Components while taking auth states into consideration:
Automatically maps a Firestore query to a RecyclerView once the user is signed-in.
Other tidbits #
For web developers, Firestore comes complete with full offline support, unlike the RTDB which had… nothing? Yep. Cheers to offline support as a first class citizen for all mobile platforms!
Also, if you’d like extra info about migrating from the RTDB to Cloud Firestore, like how to keep your data synchronized during the transition period, you’ll find documentation here.
Wrap up #
I hope you’ve enjoyed this deep dive into Firebase’s new database and are ready to start migrating your apps. Feel free to ask me any questions or clarifications!
If you’ve been enjoying quotes bashing the RTDB, here’s one last quote for your viewing pleasure:
People have made [the RTDB] work for prod apps, but they are forcing a square peg into a round hole. - Eric Kryski #
Ouch, that burns! While the RTDB may have been an uncontrollable wildfire, Cloud Firestore is a fiercely powerful flame you can wield with purpose to build better apps!